
Audio 节点(Audio Nodes)
Audio nodes 负责生成声音:语音(TTS)、配音、以及音乐/音效。你可以把文本脚本变成自然的语音,也可以用描述生成音乐。
Audio Nodes 是什么?
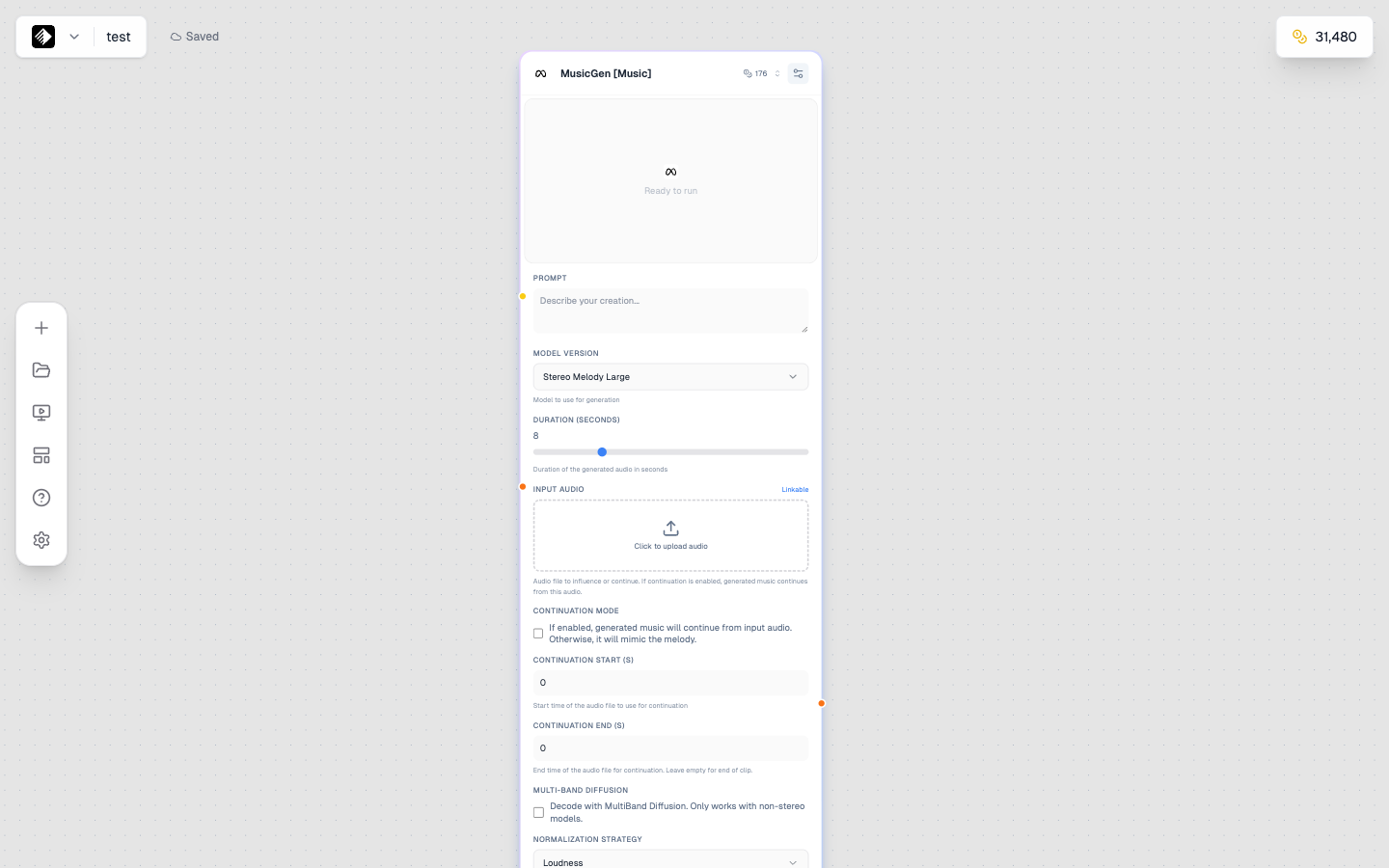
一个使用 MusicGen 的 Audio node,用于 AI 音乐生成。
Audio nodes 可以:
- 🗣️ Text-to-speech — 把脚本变成语音
- 🎵 Text-to-music — 生成音乐/配乐
- 🔊 Sound effects — 生成音效(如支持)
- 🎙️ Voice cloning — 用参考声音进行克隆(如支持)
添加 Audio Node
- 打开左侧 node sidebar
- 在列表中找到 Audio
- Drag 到画布上
Audio Node 输入(Inputs)
| Input | Type | Required | Purpose |
|---|---|---|---|
| Script / Prompt | Text (yellow) | Yes | TTS 的脚本或音乐描述 |
| Reference Audio | Audio (orange) | No | 参考声音/克隆(模型支持时) |
音频模型(Audio Models)
Text-to-Speech (TTS)
| Model | Credits | Best For |
|---|---|---|
| Speech 02 Turbo | 40 | 快速 TTS |
| Speech 02 HD | 80 | 高质量 TTS |
| XTTS v2 | 150 | 多语言、自然度高 |
Voice Cloning
| Model | Credits | Best For |
|---|---|---|
| Voice Cloning | 600 | 克隆特定声音风格 |
语音工作流(Text-to-Speech Workflow)
最常见的用法:
Prompt Template
[Text Node] → [Audio Node] Script text → Generated speech audio
Example
- 添加 Text Node
- 写一段脚本:
Welcome to Armox. Today we’ll show you how to build powerful AI workflows. - 添加 Audio Node
- 连接 Text → Audio
- 选择 TTS 模型(Speech 02 Turbo 或 HD)
- 点击 Run
音乐工作流(Text-to-Music Workflow)
如果你的 Audio node 支持音乐模型,则可以用描述生成音乐:
Prompt Template
[Text Node] → [Audio Node] Music description → Generated music
Example Prompt
Ambient cinematic music, soft piano, gentle strings,
calm and inspiring, 90 BPM
Audio Node 设置(Settings)
根据所选模型不同,可能出现:
| Setting | Description |
|---|---|
| Voice | 选择声音(性别/风格) |
| Language | 输出语言(如支持) |
| Speed | 语速 |
| Pitch | 音高 |
| Emotion / Style | 情绪或语气(如支持) |
| Seed | 复现结果(如支持) |
写好 TTS 脚本(Writing Good TTS Scripts)
让语音更自然
- 使用自然的口语表达
- 句子不要太长
- 适当使用标点(停顿很重要)
- 把数字写成更易读的形式(如 “2025” → “twenty twenty-five”)
强调与停顿
你可以通过写法引导节奏:
And then... we launched the campaign.
It was a huge success.
💡 部分模型支持 SSML;如果你在 UI 中看到 SSML 选项,请参考对应模型文档。
Voice Cloning 工作流(Voice Cloning Workflow)
使用参考音频克隆声音:
Prompt Template
[Upload Audio] → [Audio Node] ← [Text Node] Reference voice ↑ Script text └→ Generated cloned speech
Example
- 添加 Upload Node 并上传参考音频
- 添加 Text Node 写脚本
- 添加 Audio Node 并选择 Voice Cloning 模型
- 连接 Upload(audio)→ Audio(reference input)
- 连接 Text → Audio(script input)
- 运行生成
查看与下载(Viewing and Downloading)
生成完成后:
- 节点里会出现 Audio player
- 点击播放预览
- 点击 Download 下载音频文件
- 结果会自动保存到 Gallery
串联 Audio Nodes(Chaining Audio Nodes)
音频输出可以连接到:
Audio → Video(如支持)
将音频用作视频配音:
Prompt Template
[Audio Node] → [Video Node] Voiceover audio → Video with audio (if supported)
如果你的视频模型不支持直接音频输入,可在外部剪辑工具中合成。
Audio → Tool
Prompt Template
[Audio Node] → [Audio Tool] Generated audio → Processed audio
常见问题(Common Issues)
发音不自然(TTS Sounds Unnatural)
- 改写成更口语的句子
- 句子更短
- 在难读词后加停顿
- 换更高质量模型(Speech 02 HD)
语速太快/太慢
- 调整 Speed setting(如支持)
- 在脚本中用标点增加停顿
Voice cloning 不像
- 参考音频要清晰、无噪声
- 参考音频长度足够且包含多种发音
- 用同一种语言/口音输出
Use Case 示例(Use Cases)
产品解说(Product Voiceover)
Introducing the new Armox workflow builder.
Build apps in minutes. Generate content at scale.
Let’s get started.
广告旁白(Ad Narration)
Ready to boost your revenue?
Armox helps you ship campaigns faster — with AI.
Try it today.
冥想音乐(Music Prompt)
Slow ambient meditation music, soft pads, gentle bell tones,
peaceful and relaxing, 60 BPM
下一步
- Upload Nodes — 上传音频作为参考
- Audio Prompting — 音频 prompts 进阶
- Audio Workflow — 完整音频制作流程